Library
I’ve put together these guides and references from what I’ve learned designing and running systems at scale.
Whether you’re starting something new or improving what you have, you’ll find something here to help.
Pick a topic below to get started.
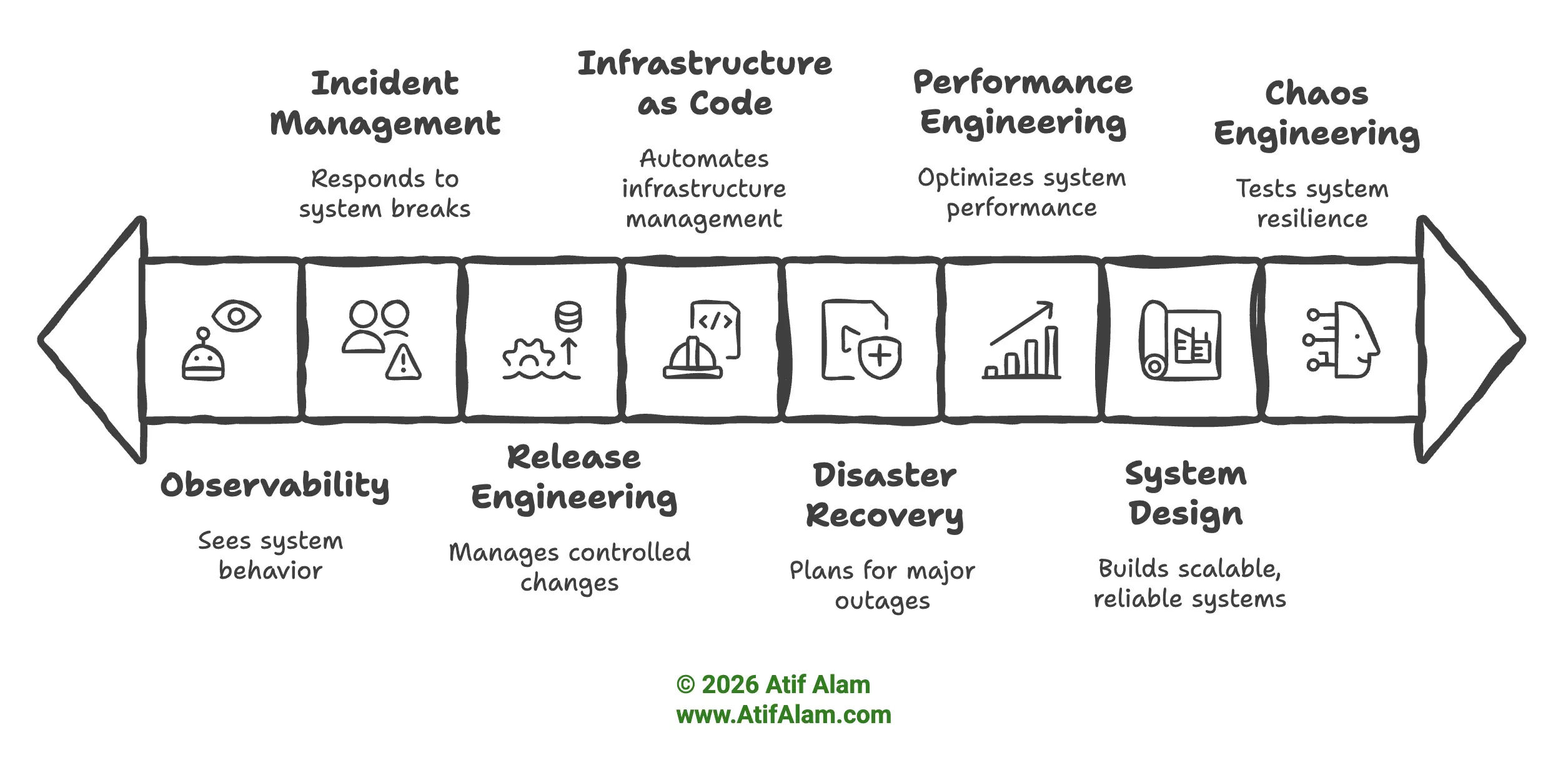
- Observability — First. You need to see what’s happening before you can improve it. (Monitoring, logging, tracing, and understanding system behavior.)
- Incident Management — Next. When something breaks, you need a clear way to respond and learn. (Practices and processes for detecting, responding to, and learning from system incidents.)
- Release Engineering — Controlled, safe changes. (Progressive delivery, feature flags, CI/CD pipelines, and change risk management.)
- Infrastructure as Code — Repeatable, auditable infra. Managing infrastructure through declarative configuration and automation.
- Disaster Recovery — Planning for major outages: RTO/RPO, backup and restore, failover, and DR testing. You need this once the business depends on the system.
- Performance Engineering — Load, capacity, cost. Matters when scale and reliability/SLAs matter.
- System Design — Patterns and principles for building scalable, reliable systems. Becomes important as you have multiple services, teams, or a platform.
- Chaos Engineering (Reliability Testing) — Validating system resilience through chaos experiments, game-days, and synthetic testing. You run chaos when you’re already relatively stable and can detect, respond, and recover.
- Mind & Machine — Exploring the intersection of human thinking and computational systems.